Imun Farmer · Published:
- 예상 수확: 5 min read
그래프DB? 온톨로지? 파헤쳐보자
그래프DB? 온톨로지? 파헤쳐보자
데이터에도 “맥락”이 필요하다
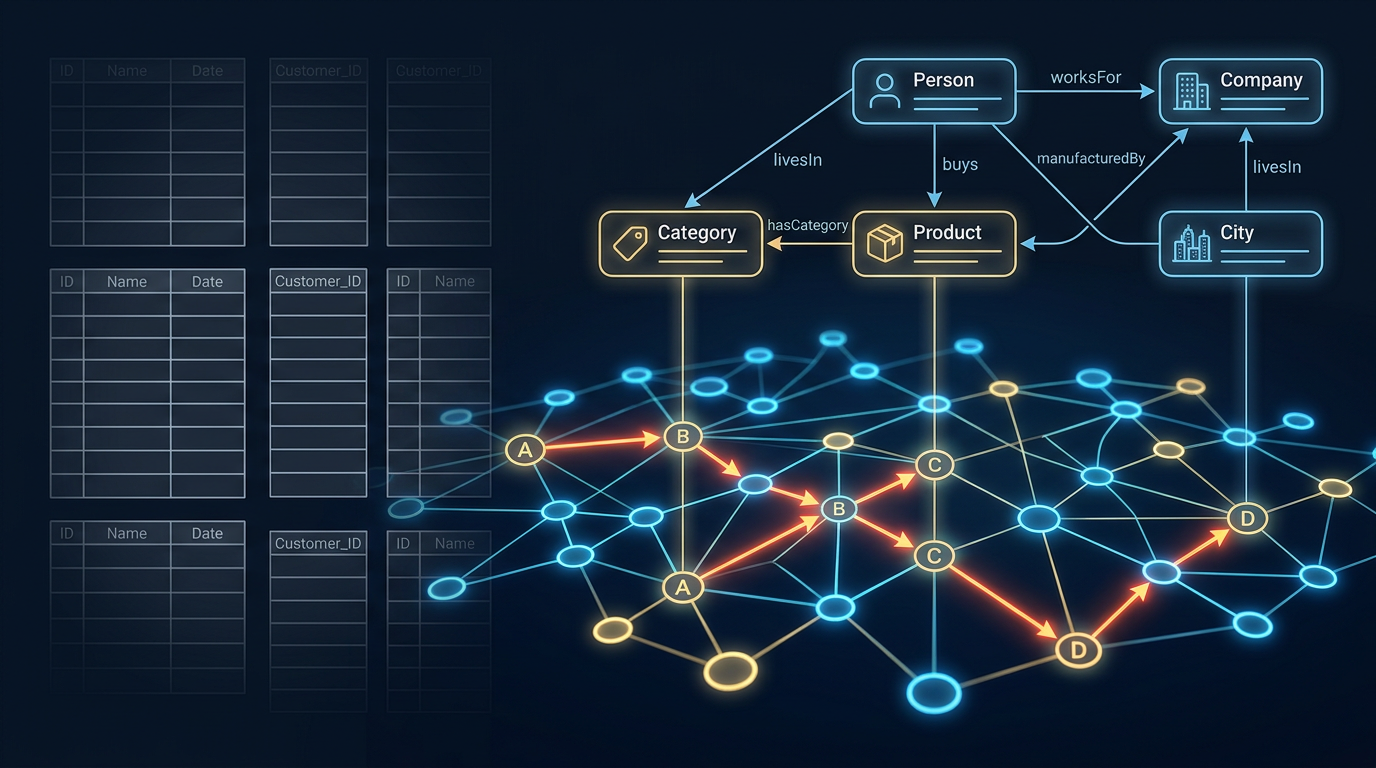
테이블을 쌓는 건 옛날 방식이다. 행과 열로 쭉 나열하면 깔끔해 보이지만, 문제는 관계다. “A 유저가 B 제품을 샀고, B 제품은 C 카테고리에 속하고, C 카테고리는 D 부서가 관리하고…” 이런 연결 고리를 SQL로 풀려면 JOIN을 4번, 5번 이어 써야 한다. 그리고 데이터가 커질수록 그 JOIN이 시스템을 죽인다.
그래프DB는 이 문제에서 출발했다. “관계를 계산하지 말고 저장하자.”
그래프DB가 뭔가
그래프 데이터베이스는 노드(Node)와 엣지(Edge)로 데이터를 표현하는 저장 시스템이다. 노드는 개체(사람, 상품, 장소)이고, 엣지는 그 개체들 사이의 관계다. 예를 들어 “톰 행크스 → [:주연] → 캐스트 어웨이” 이렇게 생겼다.
관계형 DB와 가장 큰 차이는 인덱스 프리 인접성(Index-Free Adjacency) 이다. RDBMS는 관계를 찾으려면 인덱스를 뒤지면서 Join 연산을 계산한다. 반면 그래프DB는 각 노드가 연결된 노드들의 물리적 주소를 직접 들고 있다. “친구의 친구의 친구” 같은 다단계 탐색을 데이터 전체 크기에 관계없이 빠르게 처리하는 이유가 이것이다.
그래프DB는 대표적으로 두 종류 모델이 있다.
- 속성 그래프(LPG, Labeled Property Graph): 노드와 엣지에 레이블과 속성(key-value)을 붙이는 방식. Neo4j가 이 모델을 쓴다.
- RDF 그래프: 모든 데이터를 주어-술어-객체 트리플로 표현하는 방식. 온톨로지와 연결된다.
Neo4j, 어디서 나왔나
Neo4j의 시작은 2000년이다. 창립자 에밀 아이프렘(Emil Eifrem)이 복잡한 엔터프라이즈 콘텐츠 관리 시스템을 구축하다 막혔다. 사용자-권한-파일-카테고리를 연결하는 시스템인데, 관계형 DB로 처리하면 SQL JOIN을 수없이 반복해야 했고 깊이가 깊어질수록 쿼리가 폭발적으로 느려졌다.
”왜 우리가 화이트보드에 선으로 그리는 걸 DB에서는 이렇게 복잡하게 만들어야 하나.” 이 질문 하나로 방향을 틀었다. 2002년 초기 버전을 내놓고, 2007년 오픈소스로 공개했다. 지금은 DB-Engines 랭킹 기준으로 가장 많이 사용되는 그래프DB다.
Cypher: 그림 그리듯 쓰는 쿼리 언어
Neo4j는 Cypher라는 자체 쿼리 언어를 쓴다. SQL 대신이다. 특이한 건 ASCII 아트 구문이다. 노드는 (괄호), 관계는 --[:화살표]--> 이렇게 쓴다.
MATCH (p:Person {name: "Annemarie"})-[:KNOWS]->(friend)-[:LIKES]->(c:Comment)
RETURN c
ORDER BY c.creationDate
LIMIT 100이 쿼리는 “Annemarie가 아는 친구들이 좋아요 누른 댓글 최신 100개”를 가져온다. SQL로 같은 걸 짜면 코드 길이가 4–7배 늘어난다. Cypher는 Neo4j, AgensGraph, Apache AGE, Memgraph 등 여러 그래프DB에서 지원한다.
온톨로지는 또 뭔가
온톨로지(Ontology)는 “세계를 어떻게 정의할 것인가”의 문제다. 그냥 데이터를 저장하는 게 아니라, 개념 간의 논리 구조를 정의한다. “포유류는 동물이다”, “고양이와 개는 서로 배타적인 클래스다” 같은 규칙을 집어넣는 것이다.
온톨로지를 표현하는 핵심 표준이 두 가지다.
RDF (Resource Description Framework)는 데이터를 주어-술어-객체 트리플로 표현한다. “서울 → 수도이다 → 대한민국” 이런 식이다. 모든 정보가 이 세 쌍 구조로 조각난다.
OWL (Web Ontology Language)은 RDF 위에 얹는 논리 언어다. 클래스 상속, 제약 조건, 자동 추론까지 가능하게 한다. OWL을 쓰면 “Alice는 Facilitator다”와 “Facilitator는 Role의 하위 클래스다”를 입력하면, 추론 엔진이 자동으로 “Alice는 Role이다”를 생성한다. Neo4j는 이런 자동 추론을 제공하지 않는다. 온톨로지와 그래프DB의 가장 큰 차이점이 여기 있다.
온톨로지의 쿼리 언어는 SPARQL이다. Cypher와 구조가 비슷하지만, RDF 트리플 구조에 맞게 패턴을 매핑한다.
실제로 이걸 쓰는 곳
소문만 무성한 기술이 아니다. 당장 손에 잡히는 사례들이 있다.
구글 지식 그래프. 검색창에 “이순신” 치면 오른쪽에 뜨는 정보 패널이 바로 지식 그래프 결과다. 구글은 2025년 6월에 지식 그래프를 대규모 정리했는데, 단 일주일 만에 30억 개 이상의 엔티티를 삭제했다. 모호한 데이터를 걷어내고 AI 정확도를 높이려는 전략이었다.
금융 사기 탐지. 계좌들 사이의 거래 네트워크를 그래프로 모델링하면, 정상적으로 보이지만 비정상적인 연결 패턴을 실시간으로 잡아낸다.
전자상거래 추천. eBay 같은 플랫폼은 사용자-구매이력-상품-카테고리를 그래프로 모델링해 실시간 추천을 구현한다. 관계형 DB로는 불가능한 실시간 고품질 추천이다.
의료 분야. 환자 데이터, 질병 분류, 증상, 치료법을 온톨로지로 정의하고, RDF/OWL로 복잡한 의료 지식을 모델링한다. 구글 지식 그래프, 위키데이터가 이 방식을 대규모로 활용한다.
GraphRAG: AI가 이 기술에 꽂힌 이유
요즘 그래프DB와 온톨로지가 갑자기 다시 주목받는 이유가 있다. GraphRAG 때문이다.
기존 벡터 기반 RAG는 문장의 의미 유사성을 잘 찾는다. 그런데 “A는 B의 자회사이고, B는 C 제품을 생산한다면, A와 C의 관계는?”처럼 다단계 추론(Multi-hop Reasoning)은 못 한다. 벡터는 숫자 거리를 계산할 뿐, 논리 관계를 타고 다니지 못한다.
그래서 지식 그래프를 붙였다. LLM이 텍스트에서 엔티티와 관계를 자동으로 추출해서 그래프를 만들고, 질문이 들어오면 벡터 검색으로 진입점을 찾은 뒤 그래프를 타고 연결된 지식을 확장한다. Microsoft Research 연구 결과에서 이 두 기술을 결합했을 때 전체 데이터를 조망하는 답변 능력이 크게 향상됨이 입증됐다.
LLM이 직접 쿼리 언어로 변환도 한다. 자연어 질문을 Cypher, SPARQL 같은 그래프 쿼리로 자동 번역해서 DB를 직접 조회하는 방식이다.
시장은 얼마나 크나
그래프DB 시장은 2024년 기준 약 27억 달러 규모다. 2032년까지 102억 8천만 달러로 성장할 것으로 예상되며 연평균 성장률은 18.2%다. 더 공격적인 예측도 있다. 2026년 36억 달러에서 2034년 202억 달러로 연평균 24.13% 성장한다는 전망이다.
AI와 결합한 수요 폭발이 성장을 끌고 있다. Neo4j, Oracle, AWS Amazon Neptune이 주요 플레이어로, Neo4j는 2024년 한국 맞춤 서비스 확대를 공식 발표하기도 했다.
그래서 언제 쓰냐
그래프DB가 빛을 발하는 상황이 있다. 반대로 굳이 쓸 필요 없는 상황도 있다.
| 적합한 케이스 | 부적합한 케이스 |
|---|---|
| 친구의 친구 탐색(소셜 네트워크) | 단순 CRUD, 행/열 구조 |
| 사기 탐지(이상 거래 패턴) | 집계/통계 위주 분석 |
| 추천 시스템(구매 패턴 연결) | 고정 스키마, 조인 없는 단일 테이블 조회 |
| 지식 그래프(AI 추론 강화) | 트랜잭션 처리량 극대화 |
| 코드베이스 의존성 분석 | 숫자 계산·시계열 데이터 |
온톨로지가 필요한 순간은 따로 있다. 자동 추론이 필요할 때, 즉 “이 개체가 어느 클래스에 속하는지 자동으로 판단해야 할 때”다. 의료, 법률, 복잡한 지식 체계를 다루는 도메인에서 특히 강력하다.
한 줄 정리
그래프DB는 관계를 저장한다. 온톨로지는 의미를 정의한다. 그리고 AI 시대가 오면서 이 둘이 LLM의 추론 능력을 끌어올리는 핵심 인프라로 다시 부상했다.
참고 자료
- CNF - 그래프 데이터베이스란 무엇인가?: https://www.cncf.co.kr/ebook/graphdb/part1-graph-db-and-neo4j/1-graph-database-overview/1-1-what-is-graph-database/
- 온톨로지와 RDF, OWL의 관계 (Brunch): https://brunch.co.kr/@oursophy/13
- Neo4j로 복잡한 관계 모델링 (jaenung.net): https://www.jaenung.net/tree/813
- Microsoft Fabric - 그래프 데이터베이스: https://learn.microsoft.com/ko-kr/fabric/graph/graph-database
- OWL과 RDF 차이 (티스토리): https://hyowong.tistory.com/entry/owl과-rdf-차이
- GraphRAG 백서 분석 (Brunch): https://brunch.co.kr/@msapai/8
- CNF - GraphRAG 데이터 연결이 AI 미래다: https://www.cncf.co.kr/blog/graph-rag/
- 그래프 데이터베이스 시장 보고서 (Fortune Business Insights): https://www.fortunebusinessinsights.com/ko/graph-database-market-105916
- 그래프 데이터베이스 시장 분석 (Data Bridge): https://www.databridgemarketresearch.com/ko/reports/global-graph-database-market
- Neo4j 탄생 배경 (CNF): https://www.cncf.co.kr/ebook/graphdb/part1-graph-db-and-neo4j/1-graph-database-overview/1-3-neo4j-background/
- Neo4j 개요 (devkuma): https://www.devkuma.com/docs/neo4j/overview/
- Protege와 Neo4j 차이, SPARQL 개념 (Velog): https://velog.io/@gathers/Protege와-Neo4j의-차이-그리고-SPARQL-쿼리-개념-정리
- 가장 인기 있는 그래프DB 쿼리 언어 (SKAI Worldwide): https://blog.skaiworldwide.com/557
- 구글 지식 그래프 대규모 재편 (Artience): https://www.artience.com/blog/google-knowledge-graph-ai-seo-strategy
- GraphDB 코드 구조 시각화 (stoni.space): https://stoni.space/posts/ko/graphdb/01-graphdb
- Neo4j 한국 맞춤 서비스 확대 (디지털조선): https://digitalchosun.dizzo.com/site/data/html_dir/2024/05/28/2024052880220.html
- CNF - 그래프DB 활용 사례와 기술 생태계: https://www.cncf.co.kr/ebook/graphdb/part2-graph-db-usecases-ecosystem/
Contribution to this Harvest
내용이 유익했다면 물을 주어 글을 성장시켜주세요!
(0개의 물방울이 모였습니다)